1. Кількість інформації
2. Новизна інформації
3. Якість інформації
4. Цінність інформації
5. Достовірність інформації
6. Складність інформації
7. Компресованість інформації
До числа загальних належать такі властивості інформації, які не залежать від впливу людського фактора.
1. Кількість інформації
1.1. Вимірювання
Запропоновані методи визначення кількісті інформації в різних концепціях теорії інформації описано в попередньому розділі.
У наш час можливим є вимірювання кількості інформації лише в кодах знаків. Виміряти ж кількість семантичної інформації в повідомленні (тобто інформації, поданої в значеннях слів) у наш час — неможливо. Експериментальна спроба виміряти її кількість запропоновано лише в роботі, яка описує образну концепцію теорії інформації[1] . Тому далі зупинимося лише на вимірюванні кількості інформації в кодах знаків.
Приклад. Припустімо, певне повідомлення має обсяг 344 знаки й набрано традиційним шрифтом Times New Roman. Оскільки шрифт кодує кожну літеру обним байтом, то кількість інформації в такому повідомлення становитиме 344 байт.
Приклад. Припустімо, те саме повідомлення, що й у попередньому прикладі, набрано традиційним шрифтом Arial MS Unocode, що кодує кожну літеру двома байтами. Тоді кількість інформації в такому повідомлення становитиме 344 х 2 = 688 байт.
Приклад. Так само в кількості байт можна вимірювати і кількість будь-якої іншої інформації, записаної в пам’яті комп’ютера. Але, оскільки ця інформація вже не є знаковою, то вона займатиме обсяг на кілька порядків більше, ніж та сама знакова вербальна інформація. Наприклад, коли слово „мама” займає в пам’яті комп’ютера у форматі txt чотири байти, то записане таке саме усне слово вже займатиме в 100…10000 разів більше пам'яті (залежно від якості запису).
Приклад. Обсяг тексту, набраного на аркуші паперу формату А4 в текстовому редакторі «Блокнот», буде становити близько 2 Кб. Засканована ж із такого самого формату паперу ілюстрація в форматі bmp може займати обсяг близько 1,5…2,0 Мб, тобто в тисячу разів більше.
Що стосується обсягу текстових файлів, набраних у текстових процесорах (наприклад, у Microsoft Word), то він значно перевищує кількість набраних символів, оскільки містить велику кількість службової інформації (різних видів команд). Так, файл у Microsoft Word, в якому не набрано жодного символа, має довжину більше 20 Кб.
Важливим є також питання про кількість семантичної інформації в одних і тих самих сигналах (знаках) для різних людей (наприклад, у значенні слова шахід). Тут виникає проблема визначення середньосоціальної кількості інформації в сигналі.
Гіпотеза. Кількість семантичної інформації в словах природної мови у переважної більшості людей (65…75%) однакова, а в решти — може суттєво відхилятися.
Важливим є також питання вимірювання кількості емоційної та естетичної інформації, яку сигнали можуть нести. Проте це питання поки що не вивчене (про оцінювання її кількості див. наступний підрозділ).
1.2. Оцінювання
Загальні принципи оцінювання.
Під час опрацювання найрізноманітніших повідомлень часто застосовують методи не вимірювання, а оцінювання кількості інформації, які є порівняно простішими.
Методи оцінювання мають свою специфіку: по-перше, вони різні, тобто не мають спільної одиниці вимірювання; по-друге, завжди є відносними й наближеними[2] ; по-третє, можуть бути як суб’єктивними, так і об’єктивними. Звичайно, під час опрацювання, яке здійснює людина чи комп’ютер, бажано спиратися лише на об’єктивні методи. Це означає, що методи оцінювання повинні давати такі ж результати, як і одна з концепцій теорії інформації, але у відносному й наближеному вигляді.
Як досліджено, не існує одного-єдиного методу оцінювання кількості інформації, прийнятного одночасно для всіх її видів, а тому використовують різні методи.
Загальні принципи оцінювання полягають у тому, що:
— оцінювання в деяких випадках може бути відносним (порівнювати потрібно як мінімум дві одиниці інформації);
— порівнювати можна лише одиниці одного й того ж рівня;
— оцінювати слід такими відносними оцінками як “більше”, “менше”, “дорівнює” чи “не дорівнює”;
— в окремих випадках можливе й кількісне оцінювання інформації (в кількості літер у слові, слів у реченні, речень у повідомленні чи кількості самих повідомлень).
Оцінювання кількості незнакової інформації.
Оцінювання кількості незнакової інформації будь-якого формату здійснюють у кількості байтів, з яких складається повідомлення (нагадаємо, що вимірювання кількості інформації в незнакових повідомленнях здійснюють лише стосовно формату BMP та аналогічних йому за суттю). Таким чином, одне й те ж незнакове повідомлення залежно від обраного формату запису може мати різну оцінку кількості наявної в ньому інформації.
Крім того, незнакові повідомлення (аудіоінформацію, відеоінформацію) оцінюють за кількістю одиниць часу, яку повідомлення займає в ефірі (наприклад: 30 с, 20 хв., 1 год. 15 хв. тощо).
Оцінювання кількості знакової (вербальної) інформації.
Вербальна інформація.
Оцінювання кількості інформації в повнозначних словах можна здійснювати на основі:
а) кількості літер, з яких складається знак (слово). При цьому в друкованих ЗМІ підраховують також кількість пробілів між словами (для східних (ієрогліфічних) мов — кількість ліній, з яких складається ієрогліф).
б) визначення особливостей образу фрагмента світу, що позначає слово — знак (наприклад, при різній глибині розуміння слова комп’ютер);
— чим більша кількість деталей міститься у фрагменті світу, що його позначає певне слово, і чим важче цей фрагмент правильно розпізнати, тим в цьому слові більше інформації.
Реченнєва інформація.
Інтегральною характеристикою речення є сумарна кількість наявних у ньому слів: чим більша їх кількість, тим більшою є кількість наявної в ньому інформації. Кількість слів у простих реченнях найчастіше перебуває в межах від двох (одна змінна й один предикат при відсутності кванторів) до числа, близького десяти. Середнє значення цього числа, як відомо, становить 7±2. Як максимум, дослідники виявляли в текстах речення довжиною близько сотні слів[3] .
Оцінка кількості інтегральної реченнєвої інформації відіграє особливу роль. Як встановлено ще в 30…50-х роках нашого століття, від сумарної кількості слів у сентенції вирішальним чином залежить його складність[4] . На основі цього феномену збудовані, наприклад, усі комп’ютерні системи визначення складності тексту, що функціонують у текстових процесорах (Microsoft Word, WordPerfect та ін.).
Сюжетна інформація.
Сюжетну інформацію оцінюють, виходячи з кількості речень, які містить повідомлення. Показником, що тісно пов’язаний із кількістю сюжетної інформації, є довжина повідомлення, виміряна в кількості речень (кількість речень у повідомленні дорівнює добутку кількості наявних у ньому речень, помножену на середню довжину речення, виміряну в кількості простих).
Як відомо, існує певний зв’язок між довжиною повідомлення та рівнем кваліфікації реципієнтів, які можуть сприйняти це повідомлення.
Приклад. Існують такі обмеження на довжину повідомлень для реципієнтів певних вікових груп: для наймолодших — це повідомлення довжиною, як “Казочка про курочку рябу”, для трохи старших — як “Казка про дідову доньку та бабину доньку”, для ще старших — як “Лис Микита” Івана Франка, для ще старших — як повість “Микола Джеря” І. Нечуя-Левицького, для ще старших — як “Сонячна машина” В. Винниченка, для ще старших — як трилогія про Івана Мазепу Б. Лепкого чи роман-хроніка М. Старицького “Богдан Хмельницький” (у трьох томах). На жаль, наукові дослідження про те, якою повинна бути середня довжина повідомлень для певних вікових груп реципієнтів, нам не відомі. Ці дані ще чекають своїх першовідкривачів.
Практика застосування в ЗМІ.
Таким чином, кількість знакової (вербальної) інформації оцінюють:
— у кількості літер та інших знаків у повідомленні;
— у кількості слів у повідомленні;
— у кількості речень у повідомленні;
— у кількості абзаців у повідомленні;
— у кількості повідомлень (наприклад, в одному номері газети, в одному випуску новин).
Деякі з цих показників у текстових процесорах можна визначити автоматично[5] .
У поліграфії також використовують такі одиниці оцінювання кількості інформації:
— кількість рядків;
— кількість сторінок;
— кількість авторських аркушів (один авторський аркуш — це 40 тис. знаків або 3 тис. см2 ілюстрацій).
У ЗМІ авторам (журналістам) повідомлення (інформацію) часто замовляють саме за показниками, описаними вище. Наприклад, підготуйте відеосюжет на N хв. чи рекламний аудіоролик на 30 с.
У друкованих ЗМІ журналістам матеріал можуть замовляти в кількості слів чи рядків. У книжкових видавництвах обсяг видань оцінюють в авторських, а також обліково-видавничих аркушах (обліково-видавничий аркуш відрізняється від авторського лише тим, що в його склад включають вихідні дані та іншу службову інформацію).
2. Новизна інформації
Для людини важливим є не просто отримання інформації, а отримання саме нової інформації.
Поняття новизни інформації.
Кіберентичні системи оцінюють інформацію не лише за її кількістю, а й за іншими характеристиками. Однією з найважливіших серед них є новизна: будь-яку інформацію, яка є в повідомленні, й тотожна тій, що є в пам’яті системи, оцінюють як відому (новизна — нульова; на рис. 5 це підмножина B); будь-яку іншу інформацію повідомлення, не тотожну тій, що є в пам’яті системи (відсутню в пам’яті системи), оцінюють як нову (новизна — більша нуля; на рис. 5 це підмножина A). Саме нова інформація, а не одна й та ж постійно повторювана, потрібна кібернетичним системам для адаптації й існування в навколишньому світі.
Відомим є метод, який дає змогу виявити різницю між банком інформації в момент часу t1 (It1) (відомою інформацією) і банком інформації в момент часу t2 (It2) (прирощенням до відомої інформації — нової)[6] . Ця різниця становить прирощення інформації (I):
I = It2 - It1. (30)
Одиницями оцінювання кількості нової інформації служать: біти, байти чи їх ланцюжки — для незнакових повідомлень; слова, речення чи повідомлення — для знакових повідомлень.
Оцінюючи новизну інформації, говоритимемо про різні її ступені. Так, можна використовувати як двозначну (0 — “нема”, 1 — “є”), так і багатозначну оцінку ступеня її новизни (0, 1, 2, 3 … одиниць нової інформації), що буде точнішим.
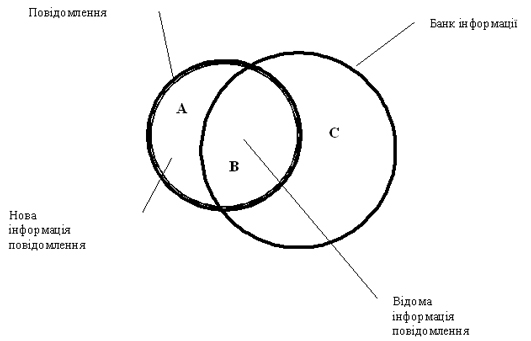
Рис. 5. Співвідношення між інформацією повідомлення та банком інформації для знакової інформації за критерієм новизни: A∩B — повідомлення; A — нова інформація повідомлення; B — відома інформація повідомлення; C∩B — банк інформації
Інструменти оцінювання новизни інформації.
Інструментом оцінювання новизни інформації є банк інформації. Таким банком інформації може виступати:
— словник, який зберігає в пам’яті кожна кібернетична система. Тут слід пам’ятати, що обсяг словника змінюється, по-перше, з розвитком людини, а, по-друге, залежить від соціальних груп, у які входить реципієнт;
— масив синтаксичних структур речень. Цей масив структур змінюється в процесі розвитку людини від від речення з одним словом до речення в кілька десятків слів;
— контекстний словник слів будь-якого окремого повідомлення, що сприймає реципієнт (цей словник поступово наповнюється при просуванні від першого речення до останнього);
— реципієнтський словник слів масиву повідомлень, що ним володіє певна реципієнтська аудиторія (наприклад, учні шостого класу; студенти спеціальності „фортепіано”; селяни; робітники; обивателі, що читають бульварні газети; обивателі, що читають інтелектуальн газети);
— суспільні словники слів масиву повідомлень, що ним володіє все суспільство (наприклад, словник усіх слів, що зафіксовані в усіх газетах; словник усіх слів, що зафіксовані в енциклопедії).
Приклад. Банками інформації є: список слів, використаних в останньому виданні енциклопедії (науковий суспільний банк інформації); список слів, використаних у газетах, переданих по радіо чи телебаченню за останні кілька років (публіцистичний суспільний банк інформації); список слів, що вжиті в підручниках з 1-го по 3-й клас включно (реципієнтський банк інформації учнів 3-го класу). Вказаний тут науковий суспільний банк інформації відтворює середній рівень знань всієї наукової еліти суспільства в певний період часу. Публіцистичний суспільний банк інформації відтворює середній, коли можна так сказати, — “обивательський” рівень знань членів суспільства певної держави (з усіма його істинними, хибними та суперечливими даними). Реципієнтський банк інформації учнів 3-го класу відтворює перелік слів, які обов’язково повинні знати учні після закінчення третього класу в конкретній країні.
Види нової інформації.
Новою може бути як незнакова, так і знакова інформація.
Новою знаковою будемо називати таку інформацію, якої нема в словнику кібернетичної системи (людини, комп’ютерної системи тощо).
Новою реченнєвою (синтаксичною) будемо називати таку синтаксичну структуру, якої нема в списку синтаксичних конструкцій кібернетичної системи (людини, комп’ютерної системи тощо).
Новою контекстною будемо називати таку інформацію, яка є в певному реченні повідомлення, але відсутня в її лівосторонньому контексті.
Новою реципієнтською будемо називати таку інформацію, яка є в певному речення повідомлення, але до моменту сприйняття цієї сентенції була відсутня в банку інформації реципієнта чи групи реципієнтів.
Новою суспільною, тобто абсолютно новою, називатимемо таку інформацію, яка є в певному реченні повідомлення, але була відсутня в банку інформації суспільства до моменту її сприйняття.
Оцінювання ступеня новизни знакової інформації.
Новою знаковою інформацією може бути:
— саме слово (неологізм), а також одночасно його значення;
— нове значення відомого слова;
— нове слово з відомим значенням, тобто синонім.
Щоби виявити нову знакову інформацію перевіряють наявність цього слова чи його значення в словнику реципієнта.
Психологічні дослідження встановили, що пасивний словниковий запас трирічної дитини становить у середньому близько 500, чотирирічної — 1500, п’ятирічної — 2000, шестирічної — 2500, а семирічної — 3000 слів[7] . До 12 років словник дитини збільшується зі середньою швидкістю 1000 слів на рік[8] , а, отже, у 12 років складає близько 8000 слів[9] .
У спеціально обраних авторами реципієнтських аудиторіях, які мають більшість спільних рис (вік, соціальні особливості тощо), індивідуальні словникові запаси меншої частини реципієнтів можуть різнитися: деякі слова, наявні в усередненому реципієнтському словнику, можуть бути відсутні в індивідуальних словниках.
Прикладом нової знакової інформації може служити поява нового синоніма до відомого слова, а також — поява у відомого слова нового значення (наприклад, у свій час слово супутник набуло, крім основного й відомого, ще одне значення: створений людиною технічний пристрій, який літає по навколоземній орбіті). На практиці обидва перелічені види нової знакової інформації можуть зустрічатися в повідомленнях не окремо, а в поєднанні (нове слово з новим значенням).
У повідомленні можна використовувати будь-яке слово лише тоді, коли воно є в словнику реципієнта. З цією метою нові слова обов'язково повинні бути пояснені в примітках (внутрітекстових чи посторінкових), а на радіо чи телебаченні — в ремарках (доповненнях) ведучого передачі.
Оцінювання ступеня новизни реченнєвої (синтаксичної) інформації.
Приклад. Для дітей початкової школи новим може бути речення, яке включає вісім чи більше змінних: Планета Земля розташована між планетами Меркурій, Венера, Марс, Юпітер, Сатурн, Уран, Нептун і Плутон. У цьому випадку для тих, хто ніколи раніше не читав тверджень із п’ятьма … вісьмома змінними, наявність п’ятого … восьмого буде новою.
Приклад. Відомим є фрагмент відомого англійського вірша, перекладеного російською мовою С. Я. Маршаком:
...Вот два петуха,
Которые будят того пастуха,
Который бранится с коровницей строгою,
Которая доит корову безрогую,
Лягнувшую старого пса без хвоста,
Который за шиворот треплет кота,
Который пугает и ловит синицу,
Котрая часто ворует пшеницу,
Которая в темном чулане хранится
В доме,
Который построил Джек!
Звичайно, це — курйозний приклад. Проте в тексті завжди можна натрапити на простіші аналоги: Іван, який тільки-но вийшов з хати, що її вчора побілила Мотря, яка сиділа на присьбі, сів поруч. Таких синтаксичних конструкцій через психологічну трудність їх сприйняття потрібно уникати. Такі синтаксичні конструкції відсутні в реципієнтів.
Оцінювання ступеня новизни контекстної інформації.
Кількість нової контекстної інформації оцінюють послідовно для кожного простого речення повідомлення, підраховуючи появу нових номенів під час його сприйняття реципієнтом зліва направо стосовно контекстного банку інформації.
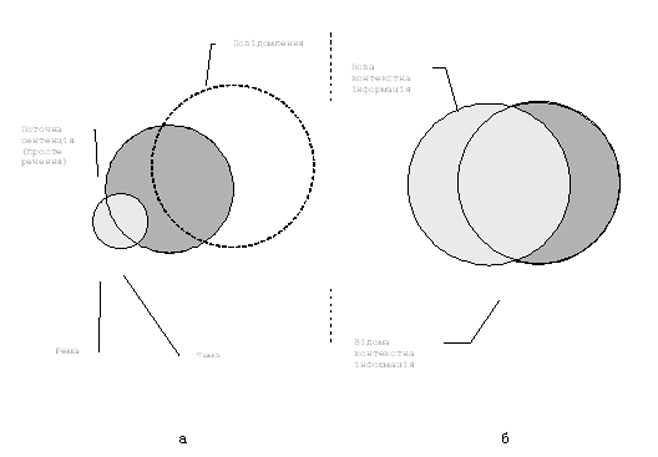
Рис. 9. Діаграми для оцінювання новизни контекстної інформації: а — оцінювання поточного речення; б — оцінювання всього повідомлення
У повідомленні нова інформація в реченнях «пульсує» порціями різної величини («квантами»). У середньому вона повинна бути рівномірно розподілена по всіх реченнях повідомлення. Це означає, що сумарна кількість нової контекстної інформації з просуванням зліва направо від 1-го до останньої m-го речення постійно зростатиме.
Приклад. У романі “Янкі з Коннектікуту при дворі короля Артура” Марк Твен чудово демонструє “перші спроби” готування газетярами репортажів:
У понеділок король прогулювався верхи в парку.
У вівторок король прогулювався верхи в парку.
У середу король прогулювався верхи в парку.
У четвер король прогулювався верхи в парку.
У п’ятницю король прогулювався верхи в парку.
У суботу король прогулювався верхи в парку.
У неділю король прогулювався верхи в парку[10] .
У першому реченні кількість одиниць нової контекстної інформації дорівнює 7 (див. структуру сентенції в розділі 4.1.3)[11] . У кожному з наступних шести речень її кількість дорівнює 1 (рис. 10). Отже, сумарна кількість нової контекстної інформації в цьому повідомленні дорівнює 13.
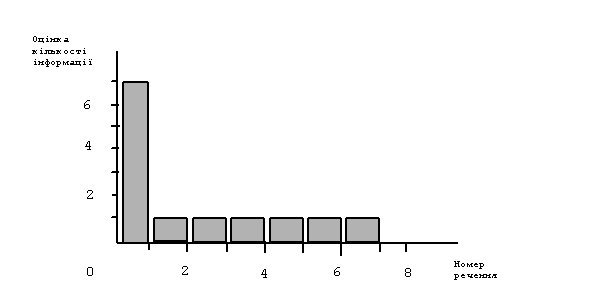
Рис. 10. Оцінка кількості нової контекстної інформації у повідомленні із семи речень
● Кількість нової контекстної інформації з просуванням зліва направо від першого до останнього речення повідомлення повинна постійно зростати.
Ця норма забороняє наявність у повідомленнях прямих чи непрямих повторень. Винятком служить навчальна література, в якій окремі сентенції спеціально повторюють для кращого запам’ятовування.
Іноді в повідомленнях для отримання спеціальних ефектів бувають і відхилення від цієї норми.
Приклад. В оповіданні Е. Хемінгуея “Присвячується Швейцарії” на початку кожної з трьох частин автор дослівно повторює одну й ту ж інформацію, яка є новою для реципієнта тільки вперше і відомою — вдруге і третє[12] . Очевидно, що автор зробив це навмисно з метою привернути в такий несподіваний спосіб увагу реципієнтів.
Приклад. Так само відомою інформацією для реципієнтів є повторення приспівів у піснях. Проте слід враховувати, що після кожного наступного заспіву приспіви завжди мають нове «контекстне» та нове емоційне значення.
● У повідомленні кожна сентенція повинна починатися відомою, а закінчуватися — новою контекстною інформацією.
У мовознавстві таке явище відоме як темо-рематичне членування речення. Порушення цієї норми веде до непов’язаності тексту — політемності.
Оцінювання ступеня новизни реципієнтської інформації.
Реципієнтську інформацію, як і контекстну, оцінюють послідовно для кожного речення повідомлення на основі появи нових слів під час його сприйняття реципієнтом зліва направо стосовно реципієнтського банку інформації.
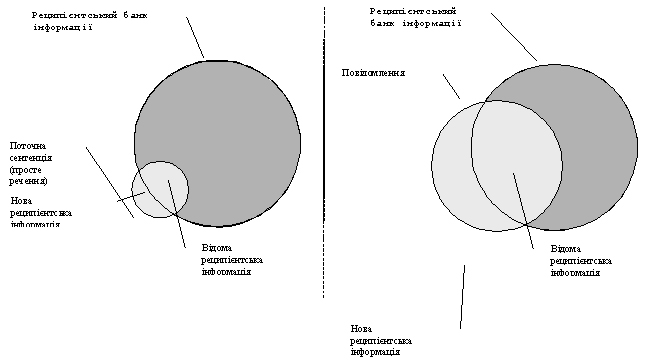
Рис. 11. Діаграма для оцінювання новизни реципієнтської інформації: а — оцінювання поточного речення; б — оцінювання всього повідомлення
Примітка. Приклад реципієнтського тезауруса для учнів сьомого класу (навчальна література) — множина всіх слів, вжитих у шкільких підручниках від першого до шостого класу.
У повідомленні нова реципієнтська інформація в реченнях «пульсує» порціями різної величини («квантами»). Як правило, вона доволі рівномірно розподілена в реченнях повідомлення. Це означає, що сумарна кількість нової реципієнтської інформації з просуванням зліва направо від першої до останньої сентенції повинна постійно зростати. Проте порівняно з контекстною інформацією її сумарна кількість є меншою, а темп прирощення — нижчий.
Приклад. Оцінимо кількість нової реципієнтської інформації у поданому вище (із Марка Твена) прикладі. Для цього приймемо, що реципієнтом цього репортажу є дошкільнята — діти трьох … чотирьох років (із простим банком інформації). Приймемо також, що в їх словниковому запасі відсутні слова понеділок, вівторок, середа, четвер, п’ятниця, субота, неділя. Тоді в цьому повідомленні в кожній сентенції кількість нової реципієнтської інформації рівна одиниці, а її сумарна кількість — семи (рис. 12). Коли б реципієнтами повідомлення були учні 11-го класу, кількість нової реципієнтської інформації дорівнювала б нулю для кожної сентенції та для цього репортажу в цілому (адже учні 11-го класу, звичайно, мають у своєму словниковому запасі слова верхи та назви днів тижня).
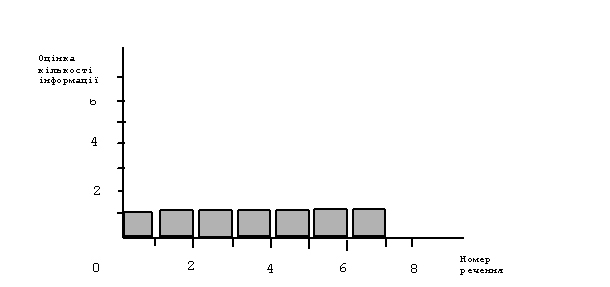
Рис. 12. Оцінка кількості нової реципієнтської інформації у повідомленні із семи сентенцій
Трудність оцінювання кількості нової реципієнтської інформації полягає, зокрема, в тому, що банки інформації реципієнтських аудиторій є динамічними (змінними в часі) та нечіткими.
У зв’язку з динамічністю банків інформації треба сказати, що в засобах масової інформації їх необхідно створювати для невеликої кількості груп реципієнтів, наприклад, для школярів (1) молодших, (2) середніх та (3) старших класів, (4) людей, які не мають вищої освіти, (5) студентів університетів, (6) людей, які мають вищу освіту, та (7) науковців[13] . Звичайно, в окремих випадках поділ на групи реципієнтів повинен бути значно детальнішим (так, під час редагування навчальної літератури для середньої школи треба утворювати банки інформації для кожного молодшого класу окремо). Наповнення банків інформації доречно змінювати не частіше, ніж раз на рік (це випливає, зокрема, з річного планування навчального процесу в середній та вищій школах). Що стосується нечіткості, то тут доречно використовувати прийом, який передбачає включення слова в банк інформації за умови, коли він є в банку інформації не менше, ніж 80% реципієнтів певної реципієнтської аудиторії.
У наш час банками інформації реципієнтів можуть служити словники-мінімуми[14] . Їх укладання є доволі тривіальним завданням. Так, у видавництвах, що публікують навчальну літературу для школи, слід укласти: а) словник слів, використаних у підручниках для 1-го класу (банк інформації реципієнтів 1-го класу); б) словник слів, використаних у підручниках для 2-го класу, плюс банк інформації реципієнтів 1-го класу (банк інформації для реципієнтів 2-го класу); в) словник слів, використаних у підручниках для 3-го класу, плюс банк інформації реципієнтів 2-го класу (банк інформації реципієнтів 3-го класу) і т. д.
Такий наближений метод надійно “працює” для підручників іноземної мови. У роботі А. В. Зубова[15] вказано, що в підручниках іноземних мов відношення кількості нових слів до всіх слів уроку повинно перебувати в межах 1,5 … 5,0%, а оптимально 3,6% (цей показник доречно називати коефіцієнтом новизни повідомлення)[16] . При цьому відношення відомих слів уроку до всіх слів, що є в банку інформації реципієнта, може перебувати в межах[17] 23,7 … 25,4% (цей показник доречно називати коефіцієнтом адаптованості повідомлення).
● Кількість нової реципієнтської інформації в повідомленні, призначеному для обраної реципієнтської аудиторії, повинна бути більшою нуля.
Ця норма забороняє наявність у повідомленні лише відомої реципієнтської інформації.
● Кількість нової реципієнтської інформації з просуванням зліва направо від першого до останнього речення повідомлення повинна постійно й рівномірно зростати.
Ця норма встановлює, що нова реципієнтська інформація не може бути присутня в одних уривках повідомлення і відсутня — в інших, а повинна бути розподілена приблизно рівномірно між усіма уривками повідомлення.
● Середня кількість нової реципієнтської інформації в кожному уривку повідомлення повинна відповідати цьому показникові, встановленому для обраної реципієнтської аудиторії.
Приклад. Для підручників з іноземних мов кількість нової реципієнтської інформації в кожному уривку повідомлення повинна становити 1,5 … 5,0% нових слів (залежно від ступеня підготованості реципієнтів)[18] .
Оцінювання ступеня новизни суспільної інформації.
Суспільну інформацію, як і контекстну та реципієнтську, оцінюють під час сприйняття повідомлення реципієнтом[19] зліва направо послідовно для кожного речення повідомлення на основі появи слів, нових стосовно суспільного банку інформації.
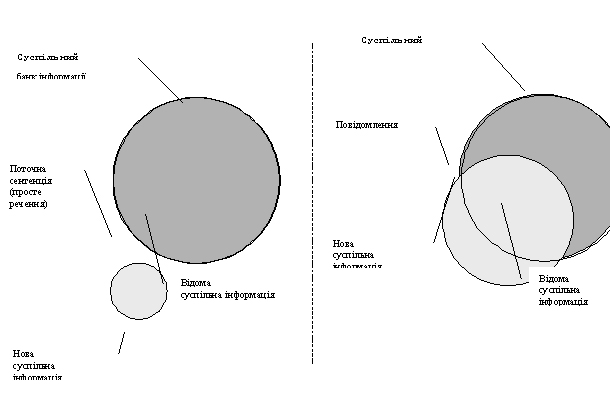
Рис. 13. Діаграма для оцінювання новизни суспільної інформації: а — оцінювання поточного речення; б — оцінювання всього повідомлення
Примітка. Приклад суспільного банку інформації для науковців (наукова література) — множина всіх слів будь-якої універсальної і галузевої енциклопедій.
У повідомленні нова суспільна інформація в реченнях також «пульсує» «квантами». Як правило, вона нерівномірно розподілена в реченнях повідомлення. Сумарна кількість нової суспільної інформації з просуванням зліва направо від першого до останнього речення може зростати, але необов’язково. У порівнянні з реципієнтською сумарна кількість суспільної інформації є ще меншою, а темп прирощення — ще нижчий.
Приклад. Новою суспільною інформацією часто є повідомлення інформаційних агентств, а також повідомлення про нові винаходи, відкриття тощо. Так, у свій час абсолютно новим були повідомлення: про відкриття нових хімічних елементів; про посадку на поверхню Місяця радянського місяцеходу; про висадку на поверхню Місяця американського астронавта; про обрання Президентом України Леоніда Кравчука; про затвердження Верховною Радою Конституції України тощо.
Приклад. Спробуємо визначити кількість нової суспільної інформації у наведеному вище (із Марка Твена) репортажі. Приймемо, що його реципієнтами є наукова еліта усього світу (з відповідним простим банком інформації). Тоді у цьому повідомленні в усіх сентенціях кількість нової суспільної інформації буде рівною нулю. Адже науковці знають усі слова, вжиті в цьому повідомленні (рис. 14).
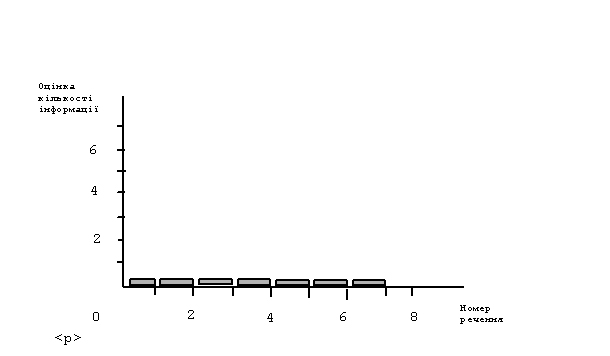
Рис. 14. Оцінка кількості нової суспільної інформації у повідомленні із семи сентенцій
Суспільний банк інформації також є динамічним та нечітким. На даний час суспільні банки інформації не укладені.
● У повідомленнях певних видів (публіцистичних, офіційних, наукових) кількість нової суспільної інформації завжди повинна бути більшою нуля.
Ця норма забороняє наявність у таких повідомленнях лише нової контекстної чи нової реципієнтської інформації. Дотримання цієї норми слід перевіряти особливо ретельно, оскільки в деяких повідомленнях, наприклад наукових, автори часто намагаються видавати нову реципієнтську інформацію за абсолютно нову.
● У публіцистичних, офіційних та наукових повідомленнях кількість нової суспільної інформації з просуванням зліва направо від першого до останнього речення повинна зростати постійно й рівномірно.
Ця норма встановлює, що нова суспільна інформація повинна бути розподілена приблизно рівномірно між усіма уривками повідомлення.
● Наявність нової суспільної інформації необов’язкова для усіх інших видів літератури (художня, популярна, інформаційна, виробнича, навчальна, довідкова, рекламна й дитяча).
● Середня кількість нової суспільної інформації в уривку повідомлення повинна відповідати цьому показникові, встановленому для обраної реципієнтської аудиторії.
* * *
Особливо актуальним є застосування критерію новизни інформації в інших галузях (наприклад, педагогіці).
* * * Оцінюючи новизну, завжди слід пам’ятати, що новою може бути не лише семантична (у широкому розумінні цього слова), а й емоційна та естетична інформація повідомлення, причому як реципієнтська, так і суспільна. Залишаючи це питання за межами роботи, скажемо лише, що для оцінювання її кількості доречно звертатися до експертів — визнаних письменників, журналістів чи науковців.
Оцінювання новизни незнакової інформації.
Оцінювання новизни незнакової інформації можна здійснювати за такою процедурою: якщо незнаковий образ розпізнаний як один із еталонних, його слід вважати відомим, а якщо як відсутній у масиві еталонних, — тоді як новий.
Кількість нових образів у незнаковому повідомленні слід підсумовувати.
Прикладами незнакових повідомлень з новими образами є:
— голоси нових дикторів (аудіальні образи);
— нові пейзажі (нові графічні образи);
— обличчя нових дикторів
3. Якість інформації
3.1. Реальність інформації
На основі описуваних світів інформацію щодо якості слід класифікувати на реальну, нереальну (псевдореальну й ірреальну) та невизначену.
Реальна інформація. Ця інформація буває істинною та хибною.
У суспільстві найвище цінується істинна інформація. На перевірку її істинності можуть витрачати значні фінансові ресурси.
Хибну інформацію, хибність якої не приховують, в побуті ще називають просто брехнею (такі “милі брéхні” часто використовують у гумористичних оповіданнях). Хибну інформацію, яку свідомо видають за істинну, називають обманом. Обман часто використовують під час виборчих кампаній, звинувачуючи супротивника в тих вчинках, яких він не робив (крадіжках, хабарах, порушенні моральних норм тощо). При цьому розраховують на те, що, поки супротивник доведе хибність висунутих проти нього звинувачень, він буде переможений.
Окремим порушенням є замовчування певних фактів реального світу, тобто непередавання реципієнтам інформації про певні факти. Замовчуваннями часто користуються “політики” певного ґатунку чи злочинці для того, щоби не зізнаватися в інших скоєних злочинах чи не видати співучасників.
За джерелом отримання реальну інформацію класифікують також на оригінальну (отриману з першоджерела — керуючої системи, яка сама першою її згенерувала) й копійовану (отриману з керуючих систем, які отримали цю інформацію з першоджерела, а далі передали іншим системам). Такий поділ дає змогу говорити про ступінь копійованості повідомлення. Звичайно, цей ступінь не мав би ніякого значення, якби під час копіювання повідомлень в нього не вкрадались системні (свідомо внесені керуючими системами) чи несистемні (випадкові) спотворення. Спотворення виникають внаслідок впливу на канал передачі інформації певних чинників, зокрема фізичних, наприклад, при передачі повідомлень каналами радіозв’язку — погодних. Як наслідок, у каналі передачі інформації з’являється така інформація (спотворення), якої джерело інформації не передавало.
Окремо слід сказати про такий вид інформації як дезінформація. Ця інформація описує не реальний, а вигаданий — псевдо- чи навіть ірреальний світ, проте видається за таку, що описує саме реальний світ, — причому за істинну. Серед дезінформацій виділяють два її види: “напівправду”, коли до правди “домішують” вигадку, та “качки”, коли інформацію вигадують повністю.
Приклад. Напівправда: Наша армія перемогла (насправді була “нічия”).
Приклад. “Качка”: Наша армія перемогла (насправді жодних сутичок зі супротивником не було).
Брехню, обман, дезінформацію та замовчування засоби масової інформації часто використовують у пропаганді[20] . При цьому виявити брехню чи обман порівняно нескладно: для цього слід лише здійснити перевірку (верифікацію) певних тверджень у реальному світі.
Складнішими для таких перевірок є дезінформація та замовчування. Проте, коли порівняти між собою ці два останні види порушень, то виявиться, що для перевірки значно складнішими є замовчування, ніж дезінформація, оскільки дезінформацію все ж можна перевірити (дезінформаційні речення не повинні мати прототипу — фрагмента в реальному світі), а замовчування не дають змоги виявити сам уривок повідомлення про фрагмент реального світу, не кажучи вже про його істинність чи хибність.
Нереальна інформація. Стосовно цього виду інформації неможливо говорити про її хибність чи істинність. Натомість говорять лише про суперечливість чи несуперечливість її сентенцій (в межах одного й того ж чи навіть кількох різних повідомлень).
Крім того, стосовно нереальної інформації в повідомленні завжди повинно бути сказано, що це саме нереальна інформація (наприклад, в анотації до книги повинно бути написано “Роман”, “Фантастика”, а в літературі для дітей — “Казка” тощо). Відсутність таких вказівок може призвести до того, що роман сприйматимуть як історичну хроніку, а казку для дорослих — як записки психічно хворої людини. Використання такого прийому загалом є забороненим.
Невизначена інформація. Цей вид інформації є найнебезпечнішим для реципієнтів, оскільки вони, як експерти, повинні самостійно визначати, до якого світу належить кожна сентенція опрацьовуваного повідомлення.
3.2. Нормованість інформації
У цілому ряді випадків інформація, викладена у формі повідомлень (текстів), повинна відповідати певним нормам, наприклад — орфографічним, логічним, композиційним, видавничим, психолінгвістичним тощо. При відхиленні від цих норм у тексті виникають помилки.
Почнемо з прикладів.
Приклад. Припустімо, в повідомленні є два об’єктивні відхилення: перше — слово дiдась (правильно — дiдусь) — в тексті й друге — прізвище автора I. I. Iваненко (правильно — Іваненко І. І.) — в бiблiографiчному описі. Стосовно першого компонента вважаємо, що в ньому є відхилення, оскільки таке слово відсутнє в орфографічному словнику української мови, а стосовно другого, — оскільки прізвище не вiдповiдає жодному зі шаблонiв, передбачених стандартом для бiблiографiчного опису (серед шаблонiв для бiблiографiчного опису є лише такий: <Прiзвище> <пробiл> Таким чином, говорячи про відхилення, завжди слід мати на увазі чотири його елементи (табл. 4-1): 1) помилковий компонент повідомлення, в якому є відхилення; 2) норму, яка є в нормативній базі і дає змогу відновити (реконструювати) правильний компонент; 3) власне помилку; 4) виправлений (реконструйований) на основі норми компонент. Неправильний компонент називають ще помилковим, тобто таким, у якому є помилка.
Таблиця 4-1
Елементи відхилення
Примітка: # - початок слова; * - кiнець слова
Спробуємо дати визначення помилки, оскільки в наявній навчальній та довідковій літературі в її визначеннях є логічні огріхи (так звані “кола”). Для цього використаємо методику, що передбачає порівняння неправильного (з відхиленням, помилкового) та правильного (нормативного, словникового) варіантів слова (табл. 4-1)[ ]. Аналогічну методику можна застосувати і для означення інших видів помилок.
Як видно з табл. 4-1, помилкою в слові дідась є літера а, що займає четверту позицію. Коли користуватися такою методикою фіксації помилок, то можна зробити висновок про те, що помилка — це об’єктивне відхилення, яке є різницею між неправильним компонентом повідомлення та його нормативним (правильним) поданням. Іншими словами, помилка — це об’єктивне відхилення, яке доповнює правильний компонент повідомлення до неправильного (помилкового). Звичайно, таке доповнення може бути і зі знаком "плюс", і зі знаком "мінус". Суб’єктивні відхилення не ведуть до появи помилок.
У наш час у ЗМІ якість тексту найчастіше визначають у наближених оцінках на зразок "у рукописі є велика (середня, мала) кількість помилок". Проте іноді важливо знати конкретніші, точніші оцінки якості повідомлення. Такі оцінки дають змогу приймати рішення (наприклад, відхилити чи прийняти рукопис, визначити потрібний ступінь його редагованості) об'єктивніше і кваліфікованіше, ніж зараз. Крім того, знання про якість повідомлень потрібне і для правильного визначення ефективності виконаного редагування (для цього потрібно принаймні знати, якою була якість повідомлення до і після редагування).
Визначення якості повідомлень. Для її визначення можна використовувати два показники: ступінь помилковості овідомлення та комплексну середню нормованість повідомлення.
Ступінь помилковості повідомлення (S) визначають так:
S = E / V, (4-1)
де E - кiлькiсть помилок у повідомленні, а V - обсяг повідомлення, в авторських аркушах (нагадаємо, що один авторський аркуш дорівнює 40 000 знаків).
Приклад. Обсяг статтi дорiвнює 0,5 авт. арк. Редактор виправив 20 помилок. Тоді ступiнь помилковостi S = 20 / 0,5 = 40 помилок на авторський аркуш.
Оскільки не всі норми чітко сформульовані, то визначити якість повідомлень в деяких випадках можна лише з певними похибками.
3.3. Інші показники якості інформації
Крім звичайної інформації, описаної в попередньому розділі, щодо якості виділяють також псевдоінформацію, параінформацію та метаінформацію.
Псевдоінформація. У повідомленні звичайна інформація постійно веде до зростання кількості нової контекстної, реципієнтської чи навіть суспільної інформації. За наявності у повідомленні псевдоінформації кількість нової контекстної, нової реципієнтської чи нової суспільної інформації практично не зростає.
Збільшенню псевдоінформації в повідомленні сприяє наявність тавтологій, перефразувань, повторів, багатозначних слів, найрізноманітніших невизначеностей тощо. Псевдоінформація в повідомленні з’являється завжди тоді, коли фактична кількість інформації значно менша, ніж та, на яку можна було б очікувати для наявної довжини повідомлення.
Специфічними виявами псевдоінформації є введення в повідомлення середньостатистичних даних, різноманітних класифікацій тощо. Це означає, що будь-яка інформація, яку реципієнт може однозначно вирахувати з повідомлення, є псевдоінформацією.
До числа класичних видів псевдоінформації належать професійно виконані гороскопи й пророцтва. Такі види повідомлень містять сентенції, які за будь-яких обставин є завжди “істинними” в реальному світі, наприклад[22] : Сьогодні слід утриматися від прийняття важливих рішень, окрім невідкладних. Реципієнтами таких повідомлень можуть бути лише ті, хто вірить у правдивість пророцтв і гороскопів.
Загалом, наявність у повідомленні псевдоінформації сама по собі не є ні доброю, ні поганою: все залежить від потреб реципієнта в отриманні такої інформації.
Параінформація. До параінформації належить така, якої нема в повідомленні в явному вигляді, тобто в значеннях його слів чи речень, проте вона випливає з нього на основі логічних виведень, підставлення замість одних змінних — інших, загальновідомих асоціацій тощо. Інакше кажучи, параінформація — це те, що написано “між рядками”. Класичним прикладом параінформації є мораль у байках.
Параінформацію часто використовують для створення гумористичних повідомлень, зокрема анекдотів, а також у виборчих технологіях з метою дискредитувати певного політика. Публікують, наприклад, повідомлення, в якому розглядають політичний портрет якогось абстрактного політика, акцентуючи тільки на його негативних рисах. При цьому реципієнти за певними деталями на підставі асоціацій можуть зрозуміти, про якого конкретно політика йде мова. Спростовувати таку параінформацію практично неможливо або вкрай важко. Спростування тут можна здійснювати лише на підставі проведених соціологічних обстежень.
Широко використовують параінформацію і в рекламних повідомленнях.
Метаінформація. Метаінформацією називають таке повідомлення, яке описує інше повідомлення.
Прикладами метаінформації є огляди преси, реферати, анотації, бібліографічні описи, цитування, відгуки, критичні статті тощо.
Ступінь метаінформування може бути різним.
Приклад. Лист про те, що Ваша стаття, яку Ви адресували в редакцію нашого журналу, буде опубліковано, надіслано Вам 12 серпня (ступінь метаінформування — 2).
У суспільстві генерування метаінформації виступає як окрема галузь суспільного виробництва. Так, у державах, як правило, є спеціально утворені організації, що займаються бібліографуванням, реферуванням і синтезуванням науково-технічних повідомлень усіх жанрів і випуском бюлетенів сигнальної інформації, реферативних журналів, оглядів розвитку всіх галузей науки й техніки. Для готування таких повідомлень вказані організації залучають велику кількість спеціально підготованих і проінструктованих спеціалістів (бібліографів, референтів, рецензентів, оглядачів тощо). Таких самих спеціалістів, як і в науці й техніці, використовують і в засобах масової інформації та мистецтві (оглядачів, критиків).
4. Цінність інформації
Поняття цінності інформації.
Про цінність інформації можна говорити лише тоді, коли перед кібернетичною системою стоїть чітка цільова функція, тобто мета.
У повідомленні цінною є така інформація, завдяки якій кібернетичні системи досягають поставленої перед собою мети[23] . Згідно з концепцією автора такого підходу А. А. Харкевича, цінність інформації (V) вимірюють як
V = log P0 – log P1, (31)
де P0 — імовірність правильного розв’язування задачі до отримання повідомлення, а P1 — імовірність правильного розв’язування задачі після отримання повідомлення.
У часі цінність інформації є величиною змінною. На неї впливає поява нової інформації щодо досягнення мети[24] .
Метою для кібернетичних систем може бути задоволення пізнавальних, емоційних, естетичних чи інших потреб, можливість виконання якихось дій тощо.
Приклад. Реципієнти можуть мати таку мету: дізнатися прогноз погоди на завтра; отримати від поетичної збірки естетичну насолоду; отримати від перегляду телевізійного фільму про кохання емоційне задоволення. Лише сприйнявши вибрані повідомлення, вони можуть встановити, чи досягли поставленої мети.
Для визначення цінності інформації потрібно мати сформульовані не тільки поточну, а й перспективну мету тих реципієнтських груп, для яких готують повідомлення. Наявність у повідомленні інформації, яка може стати корисною не лише в якийсь конкретний момент сприймання, але і в майбутньому (інформація “про запас”), різко піднімає цінність усього повідомлення.
Будемо вимірювати цінність за спрощеною методикою (у відсотках). Використовуватимемо шкалу від 0,0% до 100,0% і два види оцінок: двозначні (100,0% — цінна; 0,0% — нецінна) і багатозначні (наприклад: 0,0%; 1,0%; 2,0%; 3,0% … 100,0% — чи з вищою точністю вимірювання).
Двозначне вимірювання цінності.
Задамо функцію визначення цінності (V1) повідомлення за двозначною методикою:
V1 =
100,%, якщо M – E ≤ 0;
0,0%, якщо M – E > 0,
де M — мета повідомлення, а E — отриманий ефект.
Приклад. Без рекламної кампанії щоденний збут зубної пасти марки "Фтородент" становив 300 тюбиків. Комерсанти вирішили довести щоденний продаж до 500 тюбиків. З цією метою вони організували рекламну кампанію (передачу радіомережею рекламних повідомлень про цю пасту). Після завершення кампанії виявилося, що збут зріс до 400 тюбиків щодня.
Визначимо цінність рекламного повідомлення. Для цього найперше встановимо, що мета повідомлення склала M = 500 – 300 = 200 тюбиків і що отриманий ефект склав E = 400 – 300 = 100 тюбиків. Тоді, оскільки V1 = 200 – 100 > 0, цінність рекламного повідомлення V1 = 0,0%.
Багатозначне вимірювання цінності.
Задамо функцію для вимірювання цінності інформації за багатозначною методикою (V2) як відношення
V2 = M / E • 100%. (33)
Приклад. Цінність того ж рекламного повідомлення, виміряного за формулою (32), становить V2 = 100 / 200 = 50,0%.
Класичною задачею щодо визначення цінності інформації є задача лабіринту, коли потрібно розшукати шлях, що веде до мети — центру лабіринту. Тут цінність інформації вираховують за такою методикою. Спершу навколо центру будують коло з радіусом, який охоплює найдальшу точку лабіринту. Тоді через центр кола й точку максимального наближення шляху до центру проводять радіус кола. Далі цінність вимірюють як відношення двох відрізків: перший — частина радіуса, яка рівна віддалі від периметра кола до найближчої до центра точки, що її забезпечує обраний шлях (чисельник); другий — радіус кола (знаменник).
Слід сказати, що є інформація, яка має цінність максимально близьку до одиниці, проте ніколи не приведе до мети. Прикладом такої інформації може бути шлях у лабіринті, що макимально наближається до центру, проте ніколи до нього не доходить. Тому важливим щодо будь-якої інформації, яка визначена як цінна, знати, чи може вона в принципі привести до цілі, тобто чи має обраний варіант вирішення задачі сам розв’язок V2 = 100,0%.
Інформаційний шум.
У будь-якому повідомленні, виходячи з того, що в кожний окремий відрізок часу керуюча система має іншу мету, цінну інформацію становить, як правило, не все, а лише частина повідомлення, навіть одна чи кілька його сентенцій (наприклад, визначення терміна, юридична норма, числові дані, траєкторія руху літака-розвідника тощо). Проте, є ще й така інформація, яка обґрунтовує цінну, але сама цінною не є. Часто в повідомленні такої інформації значно більше, ніж власне цінної. Називатимемо її інформаційним шумом.
Дамо визначення: інформаційний шум — це інформація повідомлення, яка не веде до поставленої мети.
Приклад. Співвідношення цінної та нецінної інформації для випадку з лабіринтом можна визначити за кількостями входів, що ведуть до центру лабіринту, й тих, що до центру не ведуть.
Проте повідомлення не може містити лише цінну інформацію, оскільки з неї самої не завжди зрозуміла її істинність та й цілі керуючої системи постійно змінюються. Тому в будь-якому повідомленні цінна інформація завжди повинна перебувати у певному співвідношенні з нецінною (інформаційним шумом). Таке співвідношення називатимемо коефіцієнтом цінності інформації повідомлення.
Практичне застосування.
● Повідомлення обов’язково повинно включати цінну для вибраної реципієнтської аудиторії інформацію.
Ця норма забороняє наявність у повідомленні тільки інформаційного шуму.
● Кількість у повідомленні інформаційного шуму повинна бути достатньою для того, щоби реципієнт сприйняв і зрозумів цінну інформацію, але не більшою.
Ця норма встановлює, що кількість інформаційного шуму не повинна перевищувати кількості, достатньої для досягнення реципієнтом поставленої мети.
Питання цінності інформації особливо важливі під час прийняття управлінських рішень, які досліджує теорія прийняття рішень.
У повідомленні не повинно бути інформації, що веде до досягнення інших, іноді прихованих цілей (наприклад, убивства людини).
5. Достовірність інформації
Поняття про спотворення.
Копіювальні помилки (спотворення) виникають тоді, коли повідомлення копіюють (наприклад, авторський оригінал передруковують у ЗМІ після редагування, проект видання передають каналами зв’язку Інтернет зі ЗМІ у друкарню тощо). Для пошуку й видалення спотворень у ЗМІ проводять коректуру повідомлень.
Виділяють два типи спотворень: внутрілексемні та полілексемні. Внутрілексемне спотворення — це ланцюжок літер (у межах слова) в копії повідомлення від першої їх розбіжності стосовно оригіналу до найближчого збігання (див. вище табл. 4-1). Полілексемне спотворення — це ланцюжок літер у копії повідомлення (у межах усього повідомлення) стосовно його оригіналу від першої їх розбіжності до найближчого збігання[25] .
Приклад. У тексті авторського оригіналу написано: Мама купила цікаву книгу. Внаслідок дії випадкових чинників оператор набрав таку копію: Мама купла ціказу книагу. Отже, в тексті копії наявні три спотворення.
Оскільки спотворення досліджені значно краще, ніж інші види помилок, з описом їх кількісних характеристик можна познайомитися в літературі[26] .
Визначення якості повідомлень під час коректури.
Для оцінки тексту при проведенні коректури можна застосовувати також два критерії - ступiнь спотвореностi копії повідомлення та достовiрнiсть копiї повідомлення.
Ступінь спотвореності копії повідомлення (M) визначають так:
M = G / V, (4-5)
де G - кількість спотворень у тексті копії повідомлення, а V - обсяг тексту, в авторських аркушах.
Достовірності копії повідомлення (D) дають таке визначення:
D = 1 – Р, (4-6)
де Р - ймовірність спотворення знака копії тексту, причому Р = g/V, де g - кiлькiсть спотворених знакiв у текстi копiї, а V - обсяг тексту копiї з урахуванням наявних спотворених знакiв, в знаках.
Оскільки визначення величини g є трудомiстким, то для спрощення використання цього критерiю можна вважати, що
g = LG, (4-7)
де L - середня довжина спотворення (за експериментальними даними L ≈ 4,2 знака), а G - кількість спотворень у текстi копiї. Тоді вираз (4-6) можна переписати в такому вигляді:
D = 1 - LG/V. (4-8)
Перший критерій дає змогу оцінити якість тексту швидко, хоча й приблизно, а другий - точно, але трудомістко.
Приклад. Пiсля першої коректури в текстi обсягом 8,2 авт. арк. є 95 спотворень. Тоді ступінь спотвореності копії тексту M = 95/8,2 = 11,6 спотворень на авторський аркуш. Достовірність такого тексту D = 1 - (4,2 * 95) / (8,2 * 40 000) = 0,998 78.
Вимоги щодо достовірності для різних видів літератури.
Загалом, для різних видів літератури повинні бути встановлені вимоги до її достовірності, наприклад у формі стандартів. Проте ткаких стандартів немає. Незважаючи на це, в літературі подають таблиці орієнтовних вимог до різних видів літератури (табл. Х)[27] .
Способи підвищення достовірності при переачі інформації.
Для цифрових каналів зв’язку.
Для підвищення достовірності разом із кожною порцією інформації передають також контрольні розряди.
Приклад перевірки за допомогою контрольного розряду: всі коди порції інформації сумують, результат ділять на 11, а частку від ділення записують у порції як останнє число (це — контрольний розряд) й передають приймачеві. Розкодовуючи, приймач перевіряє, чи контрольний розряд (частка від ділення), який отримав він, дорівнює тому, що надіслав передавач. Якщо не рівний, то це означає, що під час передачі внаслідок шумів десь виникло спотворення повідомлення, а тому цю порцію інформації потрібно передати ще раз (передача повторюється доти, доки не буде отримано збігу контрольних розрядів).Таблиця Х
Вимоги до максимально допустимої кількості спотворень і відповідної їй достовірності інформації для різних видів літератури
Максимальна довжина контрольних розрядів може дорівнювати повторній передачі повідомлення (контроль методом дублювання). Застосування методу дублювання журналістами.
Контрольні розряди, що не відновлюють інформацію і самовідновлюють інформацію. Приклад самовідновлення для людини (відновлення при пропущених голосних у словах, спотворення окремої літери тощо).
Для передачі даних працівниками ЗМІ.
Для надзвичайно важливих повідомлень: 6. Складність інформації
Складність інформації в незнакових повідомленнях.
Для незнакового повідомлення його складність визначається тим, наскільки ми можемо задати алгоритм (функцію), яка описує його будову. Наприклад, для повідомлення
01010101010101010101010…
можна задати алгоритм, який задає чергування 0 і 1 через один розряд.
Існують і такі повідомлення, для яких задати функцію (алгоритм) неможливо. Тоді таке повідомлення буде максимально складним, а можливість знаходження його розв’язку — лищн імовірнісним, як, наприклад, у різних числових лотереях.
Розглянемо визначення складності для знакових повідомлень.
Складність інформації в незнакових повідомленнях.
Прикладом незнакового повідомлення, для якого необхідно знайти розв’язки, можуть бути різні ребуси, кросворди, головоломки, які друкують ЗМІ. Публікуючи такі повідомлення, працівники ЗМІ повинні контролювати, щоби для знаходження правильних рушень цих ребусів, кросвордів чи головоломок були хай доволі складні, але чіткі алгоритми. В іншому випадку реципієнти через надмірну складність таких повідомлень не зможуть знаходити привальних рішень, а, отже, можуть частково втратити й інтерес до видання в цілому.
Складність інформації в знакових повідомленнях.
Синтаксична складність повiдомлення.
Одним із видів складності є синтаксична складність повідомлення (іноді її називають ще читабельністю[28] ). Синтаксична складнiсть повідомлення залежить від ступеня агрегацiї одних одиниць мови — в інші (наприклад, лiтер — у слова, слiв — у речення, речень — у надфразові єдності тощо). Можна сказати, що чим бiльшу кiлькість складових має певна лінгвістична одиниця (наприклад, слово чи речення), тим важче реципієнтові встановити зв'язки мiж цими складовими (літерами, словами чи реченнями)[29] .
Існують дві групи методів визначення синтаксичної складностi. До першої, яка легко піддається формалізації, належать метод Флеша i метод CRES[30] , а до другої, яка не формалізується, — метод питань i вiдповiдей та метод резюме[31] .
Визначення синтаксичної складності для англомовних текстів. Метод Флеша визначає складність усього повідомлення чи його фрагмента (R) на основi такої формули:
R = 206,835 - 0,846N - 1,015L, (14-1)
де N — середня довжина кожних 100 слів тексту в повідомленні, в кількості складiв; L — середня довжина речень, у кiлькостi слiв.
У табл. 14-3 подана кількісна характеристика рiзних значень R для англомовних текстiв.
Таблиця 14-3
Кількісна характеристики повідомлень різної складності Метод CRES визначає складнiсть англомовних текстів за такою формулою:
R = 0,39L/P + 11,8N/L + 15,59, (14-2)
де L — середня довжина речень у фрагменті тексту, в кількості слів; P — довжина фрагмента, в кiлькості речень[33] ; N — середня довжина слів у фрагменті, в кiлькості складiв.
Метод CRES є досконаліший, оскiльки враховує ще один важливий показник, а саме — кiлькiсть речень у НФЄ. Проте цей метод не узгоджений iз поданим у методi Флеша шкалюванням складності тексту.
Ступінь складності для неформалiзованого методу питань i вiдповiдей визначають, заздалегiдь готуючи питання до повідомлення, складнiсть якого з’ясовують. Далi читачеві пропонують ознайомитися з повідомленням i вiдповiсти на підготованi запитання. За результатами вiдповiдей визначають складнiсть повідомлення (оцiнки ставлять експерти).
В іншому неформалізованому методi (методі резюме) для повідомлення заздалегiдь готують кiлька варiантiв резюме, з яких тільки одне найповніше вiдтворює змiст повідомлення. Пiсля того, як реципiєнт прочитав текст, йому пропонують вибрати саме таке. Залежно вiд вибору реципiєнта встановлюють кiлькiсну оцiнку складності повідомлення.
Визначення синтаксичної складності для україномовних текстів. Визначати складність за методом Флеша (R), адаптованим до особливостей української мови, можна за формулою[34] :
R = 206,835 - 0,283N - 5,952L, (14-3)
де N — середня довжина кожних 100 слів тексту в повідомленні, в кількості складiв; L — середня довжина речень, у кiлькостi слiв.
Проте така адаптована формула не враховує впливу довжини НФЄ. Тому доцільніше використовувати трипараметричний метод, який враховує одночасно довжину слів, речень і НФЄ та є адаптованим до шкалювання Флеша[35] . Розрахункова формула для такого методу має такий вигляд:
R = 77,0/N + 491,3/L + 8,2/P, (14-4)
де N — середня довжина слова у фрагменті тексту, в кількості літер; L — середня довжина речення у фрагменті тексту, в кількості слів; P — середня довжина надфразної єдності (абзацу), в кількості речень.
Із числа неформалізованих для україномовних повідомлень можна використовувати також метод, запропонований Б. Н. Головіним. У цьому методі складність виводять із формули[36] :
R = [D(2K - 0,5T)]/4KL, (14-5)
де D — кількість повнозначних слів в уривку повідомлення; K — кількість простих речень в уривку повідомлення; T — кількість відокремлених членів речення в уривку повідомлення; L — кількість речень у повідомленні.
На підставі проведених експериментів Б. Н. Головін підрахував, що для казки складність становить 3,9, а для наукового тексту — 15,5.
Семантична складність повідомлення.
Семантична складнiсть повідомлення залежить від кількості слів повідомлення, що відсутні в усередненому словнику реципієнтської аудиторії, за принципом: чим таких слів більше, тим повідомлення складніше й навпаки.
Формально для лінгвістичного розуміння повідомлення часто встановлюють такий критерій: слово повідомлення вважають простим, якщо воно є в словнику реципієнта, а коли нема, — складним. Для визначення ступеня складності на основі такого формального критерію укладають словники-мінімуми обсягом близько 3 тис. Слів[37] , котрі, як вважають, повинні знати всі носії певної мови, а далі перевіряють на його базі саме повідомлення. У повідомленні визначають відсоток слів, відсутніх у словнику-мінімумі. Вважають, що чим такий відсоток більший, тим складнішим для розуміння є повідомлення. Такий метод визначення ступеня складності за іменем його авторів називають методом Дейла—Челла[38] .
У методі Дейла—Челла складність повідомлення визначають із формули[39] :
R = 0,1579Q/T + 0,0496L + 3,6335, (14-6)
де Q — слова повідомлення, вiдсутнi в словнику-мінімумі загальновживаної лексики, в кiлькості слiв; T — обсяг тексту повідомлення, в кількості слів; L — середня довжина речення, в кількості слів[40] . Проте вказана формула не узгоджена з класифікацією повідомлень на сім груп за класифікації Флеша.
Враховуючи сказане, для узгодження з класифікацією реципієнтів на групи згідно з методом Флеша і для опрацювання україномовних текстів коефіцієнти формули Дейла-Челла були перераховані. У результаті формула Дейла-Челла набула такого вигляду:
R = 154,0 – 500,0Q/T - 1,5L . (14-7)
Порогові значення для віднесення конкретного повідомлення до однієї зі семи груп складності — ті самі, що й у табл. 14-3.
Практичне застосування.
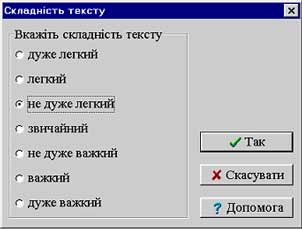
Для англомовних текстів відповідність повідомлень психолінгвістичним нормам визначають кілька ТП, зокрема Microsoft Word та Word Perfect, для російської мови — русифікавана версія Microsoft Word. Приклади такого визначення складності тексту подано на рис. 11.
Рис. 11. Вікно визначення складності тексту в ТП Microsoft Word
ТП Microsoft Word пропонує коментар до вказаних параметрів (рис. 12).
Рис. 12. Вікно допомоги до визначення складності тексту в ТП Microsoft Word
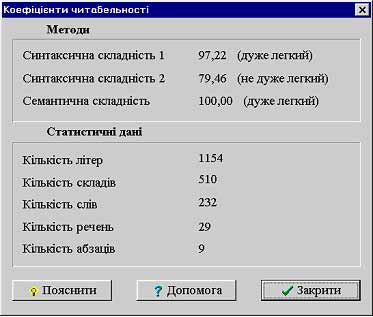
Визначення синтаксичної складності повідомлення для україномовних текстів за методами Флеша й трипараметричним реалізовано в експериментальній системі редагування “Редактор”.
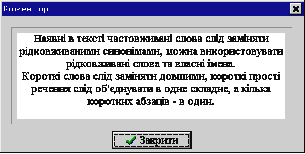
Робота зі СР “Редактор” передбачає, що в систему найперше завантажують текст, який повинен підлягати контролю. Визначення складності відбувається в діалоговому режимі. Передусім користувачеві пропонують повідомити, для якої реципієнтської аудиторії він підготував своє повідомлення (рис. 18-9). Далі СР визначає фактичну синтаксичну складність повідомлення (рис. 18-10). При бажанні користувач може отримати пояснення, що йому слід зробити для того, аби фактична складність повідомлення відповідала запланованій, тобто відповідала обраній автором реципієнтській аудиторії (рис. 18—11).
Рис. 18-9. Діалогове вікно СР “Редактор” для вибору користувачем реципієнтської аудиторії, для якої підготовано повідомлення
Рис. 18-10. Вікно визначення синтаксичної складності повідомлення СР “Редактор”
Рис. 18-11. Пояснення до визначення синтаксичної складності повідомлення СР “Редактор”
Ефективність визначення семантичної складності повідомлення істотно залежить від якості укладеного словника-мінімуму.
Визначення семантичної складності відбувається за тією ж послідовністю дій, що й для синтаксичної. Результати роботи системи виводяться на екран паралельно для синтаксичної та семантичної складності (див. вище рис. 18-10 і 18-11).
7. Компресованість інформації
Виділяють компресування (ущільнення) інформації та її розширення.
Сутність компресування.
Під час готування й передачі повідомлень часто виникає таке завдання: скомпресувати (ущільнити) інформацію повідомлення так, щоби вона була в меншому, ніж це є, об’ємі носія інформації або щоб її можна було передати за коротший відрізок часу. Зменшення об’ємів веде до розроблення досконаліших носіїв інформації, а зменшення тривалості часу передачі — до вибору оптимальніших способів кодування інформації.
Розрізняють два загальні способи компресування інформації: перший — без втрати інформації (як для знакових, так і для незнакових повідомлень; наприклад під час архівування файлів на комп’ютерних носіях інформації); другий — із втратою частини інформації (наприклад, під час готування повідомлень у ЗМІ для знакових повідомлень залишають тільки цінну інформацію і видаляють інформаційний шум).
Компресування незнакової інформації.
Найширше використовують ті носії й ті канали, які за співвідношенням “кількість інформації в одиниці об’єму / ціна” і “кількість інформації за одиницю часу / ціна” мають оптимальне значення.
Для компресування в комп’ютерах використовують програми-ущільнювачі — архіватори. Залежно від особливостей опрацьовуваної інформації, способу архівування та деяких менш важливих параметрів ці програми можуть ущільнювати інформацію в кілька разів. У наш час типовими і найрозповсюдженішими програмами-архіваторами є ZIP, RAR, ARJ, LHA та деякі ін.
Що стосується подання для реципієнтів тієї самої аудіальної чи візуальної інформації за менший відрізок часу, то тут існують чіткі обмеження — це час, за який людина може сприйняти й розпізнати інформацію. Зменшення часу сприймання може призвести лише до того, що інформацію не сприймуть чи не розпізнають взагалі. Тому такі ущільнення, загалом, неприйнятні.
Структура знакового повідомлення з позиції компресованості інформації.
Елементи повідомлення можна класифікувати за ступенем скомпресованості в них інформації. Скомпресовані елементи достатньо часто використовують, щоби полегшити реципієнтам пошук потрібної інформації. У публіцистичних видах літератури – це короткий виклад новин у передтекстах (анотаціях[41] ), за яким іде повний; у наукових – це реферати статей чи монографій; у художніх – компедіуми, які йдуть після назви розділу перед самим текстом. Співвідношення між повним текстом повідомлення та його скомпресованими варіантами показано на рис. 15. Тут зверху над повним текстом перелічено скомпресовані напівзв’язні зв’язні тексти у формі термінів (ключових слів — словосполучень) і називних речень (назв рубрик змісту й всього повідомлення), а внизу — зв’язні тексти у формі реферату й анотації.
Компресування знакової (вербальної) інформації.
Розглянемо, як у меншому за обсягом тексті (відносно оригіналу) подати ту саму кількість інформації.
Для знакових повідомлень компресування має конкретизовані формулювання вказаної загальної задачі — подати: (а) повідомлення в меншій, ніж це є, кількості байтів; (б) в меншому за обсягом тексті ту саму кількість інформації; (в) подати той самий текст на меншій площі носія інформації (паперу тощо); (г) подати той самий текст у виданні меншого обсягу; (ґ) подати ту саму аудіальну чи візуальну інформацію за менший відрізок часу; е) видалити з повідомлення інформаційний шум, що, звісно, може призвести до певного зниження ступеня його зрозумілості.
Приклад. Повернемося до репортажу з роману Марка Твена. На першому етапі його текст можна скомпресувати в такий спосіб:
У понеділок, вівторок, середу, четвер, п’ятницю, суботу й неділю король прогулювався верхи в парку.
Таке речення матиме вже 13 одиниць нової контекстної інформації, що може бути явно забагато для реципієнтів низького рівня кваліфікації. Тому на другому етапі це речення можна скомпресувати в такий спосіб:
Увесь тиждень король прогулювався верхи в парку.
У науковій літературі можуть використовувати інші способи компресування, зокрема такі: а) замість довгого вербального тексту ті самі дані подають у вигляді таблиці; б) замість вербального тексту чи таблиці дані подають в аналітичному вигляді — формулою; в) «запаковують» інформацію в спеціальні шаблони (наприклад, інформацію про видання — у шаблон бібліографічного опису).
Для подання того самого за обсягом тексту на меншій площі чи на меншій кількості сторінок використовують інші способи. Так, для ущільнення інформації застосовують шрифти спеціальних гарнітур, які дають змогу зекономити близько 10% площі паперу, а також спеціальні сорти паперу, які мають меншу, ніж звичайно, товщину. Така потреба в компресуванні іноді виникає при виданні однотомних довідників (енциклопедій, словників тощо). Інколи для конкретного видання навіть розробляють спеціальні гарнітури шрифтів і спеціальні сорти паперу, призначені лише для цього видання. Проте такі методи компресування мають свої обмеження: вони можуть бути використані лише для деяких видів літератури (наприклад, довідкової), що розраховані лише на вибіркове, а не наскрізне читання.
Компресування — це також і анотування, і реферування інформації (їх визначення див. далі). Існують комп’ютерні системи реферування. Іноді такі системи реферування включають у вигляді функцій в склад текстових процесорів (наприклад, у Microsoft Word це Сервис / Автореферат…).
Для компресування повідомлень, призначених для передачі ЗМІ, найчастіше використовують скорочення, тобто один із методів виправлення (редагування) тексту. Існують типові алгоритми такого скорочення.
Скорочення найефективніше виконувати в такий спосіб:
Сутність розширення інформації.
Значно рідше виникає протилежна потреба — розширити наявну кількість інформації. Наприклад, заповнити залишок (30 с чи 1 хв. 15 с) ефірного часу або певну площу сторінки друкованого видання (наприклад, доповнити матеріал двома абзацами чи дев’ятьма рядками).
Алгоритмом розширення інформації для знакового повідомлення може слугувати:
Прикладом „злоякісного” розширення незнакової інформації можуть служити програми-віруси, які самокопіюються („розмножуються”) і в такий спосіб заповнують носій інформації, внаслідок чого комп’ютер може вийти з ладу.
Визначення ступеня компресування інформації.
Для оцінки ущільненості використовують такий критерій як ступінь компресування інформації (C). Його можна вираховувати як відношення значення вибраного показника (кількості знаків, площі, об’єму, часу, пам’яті) перед компресування до значення того самого показника після компресування, тобто
C = P1 / P2 • 100%, (34)
де P1 — значення показника до компресування, а P2 — значення показника після компресування.
Приклад. Подана вище цитата з роману Марка Твена (див. вище) має обсяг 308 знаків (із врахуванням пробілів і розділових знаків). Скомпресована інформація (У понеділок, вівторок, середу, четвер, п’ятницю, суботу й неділю король прогулювався верхи в парку.) містить 99 знаків, а ще більше скомпресована (Увесь тиждень король прогулювався верхи в парку.) — 48 знаків. Таким чином, для першого варіанта C = 308 / 99 = 311%, а для другого C = 308 / 48 = 642%.
Ступінь розширення інформації можна розраховувати за іншою формулою:
U = P1 / P2 • 100%, (34)
де U1 — значення показника після розширення, а U2 — значення показника перед розширенням.
Практичне застосування.
Покажемо можливість застосування критерію скомпресованості інформації під час готування знакових повідомлень — текстів.
Під час готування щодо ступеня компресування слід користуватися такими нормами.
● Якщо в повідомленні існує можливість компресувати інформацію без втрати її кількості, то її компресують незалежно від виду літератури, використовуючи найнижчий ступінь компресування.
● У довідковій, інформаційній і рекламній літературі інформацію подають лише в скомпресованому вигляді з найвищим ступенем компресування.
● У публіцистичній літературі інформацію треба подавати з середнім ступенем компресування.
● Ступінь скомпресованості повинен бути таким, щоби не блокувати і не сповільнювати сприйняття реципієнтською аудиторією поданої інформації.
Якщо компресування інформації унеможливлює її сприйняття, ступінь компресування слід зменшити.
● У ЗМІ розширення інформації слід уникат Виноски:
Елементи відхилення
Порядковий номер знака 0 1 2 3 4 5 6 7
Помилковий компонент # д і д а с ь * Норма # д і д у с ь * Помилка # а * Виправлений компонент # д і д у с ь *
Види видань Кількість спотворень на 1 авт.арк. Середнє значення достовірності 1 Іноформаційні видання (бюлетені сигнальної інформації) 10,5-14,5 0,998 70 2 Виробничо-технічні видання (звіти, інструкції, пояснювальні записки тощо), інформаційні видання (реферативні журнали, огляди) 5,5-7,5 0,999 32 3 Видання художньої літератури (сучасної), масово-політичної, науково-популярної та науково-технічної літератури (у тому числі відповідні типи журналів) 4,5-5,5 0,999 48 4 Видання навчальної літератури, видання класиків літератури й науки, газети 2,3-3,5 0,999 69 5 Офіційні видання (кодекси законів, постанови уряду тощо) 1,7-2,3 0,999 79 6 Довідкові видання, словники 0,8-1,2 0,999 90 7 Енциклопедії, прейскуранти 0,4-0,6 0,999 94
— повторно передати повідомлення, тобто продублювати його передачу;
— постаратися передати повідомлення іншим каналом зв’язку.
N
L
R Складність повідомлення > 192 > 29 0…30 Дуже важкий 167 25 31…50 Важкий 155 21 31…60 Не дуже важкий 147 17[32] 61…70 Звичайний 139 14 71…80 Не дуже легкий 131 11 81…90 Легкий <123 <8 91…100 Дуже легкий 

— визначити рівень, на якому слід провести скорочення (наприклад, на рівні слів, речень чи надфразових єдностей —абзаців);
— вибрати шкалу для експертних оцінок (наприклад, шкалу з трьох оцінок: 1, 2 і 3);
— біля всіх компонентів визначеного рівня поставити експертні оцінки, що вказують на ступінь відповідності компонента основній темі чи меті повідомлення (наприклад, найвища оцінка “3” відповідає найбільшій відповідності, а найменша “1” — найменшій);
— видалити з повідомлення компоненти, оцінки яких свідчать про те, що вони найменше стосуються основної теми чи мети повідомлення.
— деталізація інформації (додавання нових подробиць до наявного повідомлення — аудіального, відео чи знакового);
— збільшення кегля літер, віддалей між літерами чи рядками, збільшення величини абзацного відступу тощо.
1. Партико З. В. Образна концепція теорії інформації. Монографія. Л: Видавн. центр ЛНУ ім. І. Франка, 2001. 134 с.
2.Ці методи доречно базувати на теорії нечітких множин і, відповідно, ймовірнісній логіці.
3. Див.: Андреев Н. Д. Статистико-комбинаторные методы в теоретическом и прикладном языкознании. Ленинград: Наука, 1967. С. 248-260. Тут не беремо до уваги періоди, які, фактично, є множиною низки простих, складнопідрядних, складносурядних і складносуряднопідрядних речень, розділених крапкою з комою.
4. Flesh R. The art of readable writing. New York: Harper & Row, 1974.
5. Наприклад, у текстовому процесорі Microsoft Word — це функція Сервис / Ситистика.
6. Шрейдер Ю. А. Об одной модели семантической теории информации. // Проблемы кибернетики. Вып. 13. М.: Наука, 1965.
7. Lefton L. A., Valvatne L. Mastering Psychology. 3-d ed. Boston, L., Sydney, Toronto: Allyn and Bacon, Inc., 1988. P. 329.
8. Faw T., Belkin G. S. Child psycology. NY: McGraw-Hill Publishing Company, 1989. P. 377.
9. Дані для наступних вікових груп у літературі не наводять.
10. Твен М. Твори: В 2-х т. К.: Дніпро, 1985. Т. 2. С. 165.
11. Подамо методику підрахунку: значення квантора відношення до дійсності “псевдореальність” — один, час “у понеділок” — два, місце “у парку” — три, кількість (виводиться із тексту) “<один>” — чотири, змінна “король” — п’ять, предикат “прогулювався” — шість, змінна “верхи <=на коні>” — сім).
12. Хэмингуэй Э. Избранное. Кишинев: Картя Молдавеняскэ, 1974.
13. Такі поділи на сім груп, як правило, використовують у видавничій практиці при визначенні складності тексту (див., наприклад: Severin W. J., Tankard J. W. Jr. Communication Theories. 2-d ed. New York, London: Longman, 1988. P. 69-87). При цьому реципієнтів з вищою освітою іноді стосовно будь-якої теми додатково ділять на фахівців і нефахівців.
14. Ардан Р. В., Бацевич Ф. С., Партико З. В. Комп'ютерний словник-мінімум української мови. // Мовознавство. 1996. № 4-5. С. 34-40.
15. Зубов А. В. Обработка на ЕС ЭВМ текстов естественных языков. Минск: Вышейшая школа, 1977. С. 148.
16. Цей коефіцієнт у певному розумінні близький до того, що в теорії редагування називають “напругою викладу” (Іванченко Р. Г. Літературне редагування. 2-е вид. К.: Вища школа, 1983. С.96-118).
17. Зубов А. В. Обработка на ЕС ЭВМ текстов естественных языков. Минск: Вышейшая школа, 1977. С. 159.
18. Зубов А. В. Обработка на ЕС ЭВМ текстов естественных языков. Минск: Вышейшая школа, 1977.
19. Реципієнтами, що володіють суспільним банком інформації (в окремих питаннях) є, як правило, вчені найвищого рівня кваліфікації (вчені-експерти).
20. Ми не торкаємося тут питання про юридичну чи моральну дозволеність таких явищ.
21. Партыко З. В. Статистика ошибок при корректуре и редактировании текстов. М.: Книжная палата, 1989. 56 с. (Издательское дело: Обзорная информация / НИЦ "Информпечать; вып. N3).
22. Слова з нечітким значенням, а також суперечливі твердження підкреслено.
23. Харкевич А. А. О ценности информации // Проблемы кибернетики. 1960. № 4. С. 53-57
24. Бонгард М. М. О понятии “полезная информация” // Проблемы кибернетики. Вып. 9. М.: Физматгиз, 1963. С. 71-102.
25. Партыко З. В. Статистика ошибок при корректуре и редактировании текстов. М.: Книжная палата, 1989. 56 с. (Издательское дело: Обзорная информация/НИЦ "Информпечать; вып. N 3).
26. Партыко З. В. Статистика ошибок при корректуре и редактировании текстов// Издательское дело: Обзор. информация/ Информпечать. - 1989. - Вып. 3. - 56 с.
27. Партыко З. В. Статистика ощибок при корректуре и редактировании текстов. Издательское дело. Обзорная информация. Вып. 3. М.: Книжная палата, 1989. С. 41.
28. Термiн "читабельнiсть" походить вiд англiйського слова "readability" (у перекладі — зрозумiлiсть, доступнiсть). У читабельностi, крім складності, виділяють ще графiчну форму подання повідомлення (шрифти, формати, видiлення тощо).
29. Слід сказати, що існує окремий розділ кібернетики — теорія складності.
30. Иванов Р. Н. Организация и методика информационной работы. Москва, Радио и связь, 1982; Kincaid R. Y., Aagard Y. A., etc. Computer readability edition system./ IEEE Transaction on professional communication. 1981. V. PC-24. N 1. P. 38-41.
31. Иванов Р. Н. Организация и методика информационной работы. М.: Радио и связь, 1982.
32. В усномовному спілкуванні (радіо, телебачення, кіно) середня довжина речення не повинна перевищувати 12 … 13 слів (Справочник по инженерной психологии. М.: Машиносроение, 1982. С. 85).
33. Тут пiд фрагментом тексту розумiють або весь текст, або його частину (роздiл), або надфразну єднiсть.
34. Формула розрахована Д. А. Герасимовим та З. В. Партиком.
35. Партико З., Бородчук В., Сорокатий І. Трипараметричний метод визначення читабельності (складності) україномовних текстів. // Палітра друку. 1995. N 4. С. 54-55.
36. Головин Б. Н. Язык и статистика. М.: Просвещение, 1971.
37. Такі словники-мінімуми вже давно існують для англомовних текстів. Єдиною спробою подібного словника можна назвати описаний в роботі: Ардан Р. В., Бацевич Ф. С., Кінах І. Я., Партико З. В. Комп'ютерний словник-мінімум української мови / Мовознавство. 1996. N 4-5. Сс. 34-40.
38. Baskette F. K., Sissors J. Z., Brooks B. S. The Art of Editing. 5-th ed. NY, Toronto: Macmillan Publishing Company, Maxwell Macmillan Canada, 1992. P. 21; Иванов Р. Н. Организация и методика информационной работы. Москва, Радио и связь, 1982. С. 66.
39. Dale E., Chall J. S. A formula for predicting readability. // Educational Research Bulletin. 1948. N 27. P. 11-20, 37-54.
40. У цій формулі, крім кількості слів, відсутніх у словнику-мінімумі (перший доданок), у другому доданку визначають також синтаксичну складність повідомлення, проте її вага в цій формулі, як свідчить величина коефіцієнта, мала.